The Art of True Humanization: Why Lowering
Lowering AI detection scores alone does not guarantee quality or authenticity. True AI humanization focuses on preserving meaning, maintaining logical structure, and enhancing emotional flow through burstiness, rhythm, and clarity. By evaluating humanized content using multidimensional metrics such as faithfulness, controllability, writing quality, and AI risk, creators can ensure AI-assisted writing remains accurate, readable, and genuinely human.
In the midst of today's AIGC explosion, we seem to be trapped in a game of cat and mouse. Everyone is fixated on automated detection and single-number “AI scores,” treating them as the only measure that matters.
But deep down in the technical trenches, we've uncovered a truth that many overlook:
"Even if an AI Humanizer drives the AI score down to zero, if it crushes the original meaning or breaks the logical structure, its existence is utterly meaningless."
AI Humanizer shouldn't just be a "master of disguise" designed to trick detectors. It should be a "Master Polisher." Its goal isn't merely to lower a number, but to infuse cold text with warmth, with human rhythm (Burstiness), and with genuine resonance that connects with the reader.
Let’s look at this through a technical lens. Using a structured evaluation framework, we can outline what high-quality humanization looks like in practice.
Redefining the Goal: It's Not Just "Spinning" Content
Many people mistake Humanizers for old-school article spinners, but modern writing tools focus on preserving meaning, structure, and emotional flow rather than simple word replacement.
In a professional evaluation system, the Input might be robotic, hollow, or loosely structured. But the Output must adhere to three unshakable "Hard Constraints":
-
Meaning Preserved: The core argument cannot shift.
-
Information Retained: Key data, entities, and terminology must be kept precise.
-
Engagement Improved: It needs to feel like a human wrote it—full of emotion and flow.
If a tool changes "connect via API" to "connect via hole" just to lower the AI score, that Humanizer has failed.
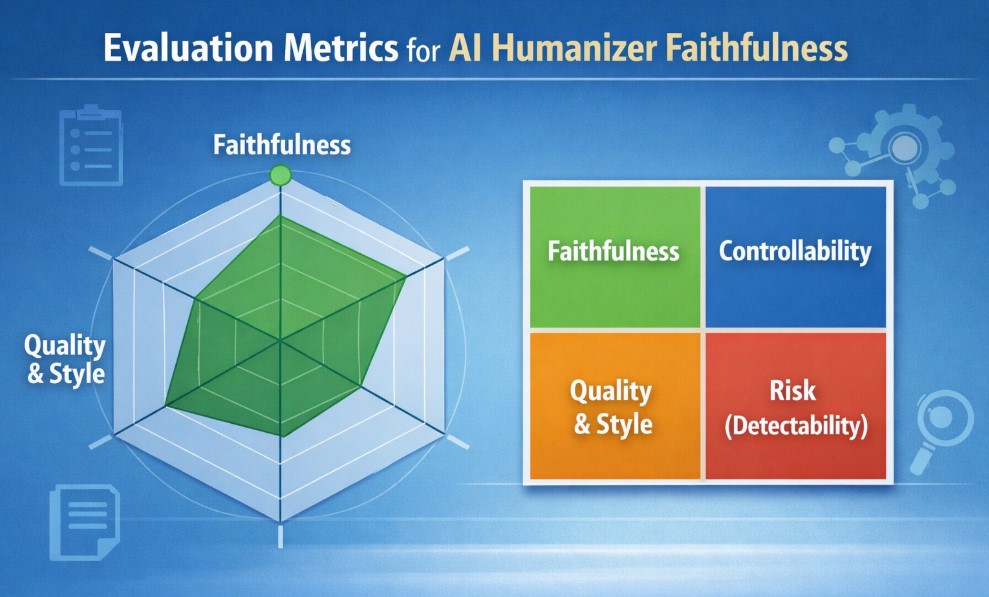
Rejecting Single Metrics: We Need a "Radar Chart"
To scientifically measure "humanness," looking at a single percentage point isn't enough. We recommend a comprehensive 4-Dimensional Evaluation Framework. This isn't just a standard for products; it's a guide for users choosing their tools.
1. Faithfulness: Is it honest?
This is the baseline. How do we use tech to ensure the machine isn't hallucinating?
-
Semantic Similarity: We look beyond surface words to the "vector space." We use vector models like Sentence-BERT or E5 to calculate the Embedding Cosine Similarity between input and output.
-
Logical Entailment (NLI): This is an advanced technique. We use Natural Language Inference (NLI) models to verify that the new sentences logically align with the original ones, preventing any "cause-and-effect" reversals.
-
Entity Recall (NER): Using spaCy or KeyBERT, we ensure key figures (like "2025") and proper nouns (like "Transformer") aren't accidentally swapped out.
2. Controllability: Does it follow the rules?
AI models deal in probabilities, so they love to ramble.
-
Length & Structure Control: We calculate the Length Ratio to ensure the text isn't maliciously padded or over-compressed. We also use Markdown Parsers to verify headers and lists, ensuring the document structure remains rigorous and clean.
3. Quality & Style: Does it have a soul?
This is the hardest, most beautiful part. Human writing has a heartbeat.
-
Perplexity (PPL): PPL measures how "surprised" a model is by the text. Generally, AI text has a low, flat PPL. Human text is higher and more unpredictable.
-
Burstiness: This measures "rhythm." Humans write with variance—sometimes long, flowing sentences; sometimes short, punchy ones. We quantify this "chaotic beauty" by analyzing sentence length variance and vocabulary diversity.
4. AI Traces & Risk (Detectability): Is it safe?
Only now do we talk about the AI rate.
-
Ensemble Detection: Don't trust a single detector. The professional approach is to integrate multiple algorithms—like RoBERTa and DetectGPT—to generate an AI Risk Score, rather than a raw percentage. The AI rate is a risk warning, not the ultimate goal.
- Multi-Layered Detection: In practice, platforms utilize a multi-layered ai detector framework to catch complex structural patterns that single models miss."
Insertion point: After the existing text, "to generate an AI Risk Score, rather than a raw percentage.
Technical Traps & Advice
For the developers and geeks reading this, understanding the logic behind these metrics is crucial.
-
Beware the "Synonym Trap": Simple word swapping (which might pass low-level checks) destroys Perplexity (PPL). It makes the article read like it was written by an alien.
-
Don't Sacrifice Readability for Burstiness: Forcing sentence variance without logical support makes the text feel disjointed. A great Humanizer finds the perfect rhythm while maintaining Logical Consistency.
Final Thoughts: Bringing Tech Back to Humanity
In this age of AI saturation, we find ourselves cherishing human traits even more: our imperfections, our emotions, our ups and downs.
An excellent AI Humanizer isn't defined by "hacker tricks." It's defined by a deep understanding and deconstruction of the art of language. It doesn't just need to know algorithms; it needs to know literature. It doesn't just need to pass detection; it needs to move the reader.
Looking at current industry practices, few implementations consistently meet a “multi-dimensional, explainable, and reproducible” standard. The more reliable direction is not brute-force rewriting, but preserving the original logic and emotional tone while improving clarity and flow.
That balance is where AI-assisted writing can be most valuable.

Subscribe & get all related Blog notification.



Post your comment